GPT-5 Series vs. Gemini 3 Pro: The Verdict from SuperGPQA
The release of OpenAI’s GPT-5.2 Pro has reignited the race for AI supremacy, promising significant leaps in reasoning and professional capabilities. But how does it actually perform when tested against the world's hardest domain-specific questions?
We put the leading frontier models—including Google’s Gemini 3 Pro Preview, GPT-5.2 Pro, and GPT-5.1-Thinking—to the test on SuperGPQA, our gold standard benchmark for graduate-level knowledge covering 285 specialized disciplines from Quantum Mechanics to Agronomy, SuperGPQA bypasses surface-level internet knowledge to evaluate deep reasoning.
The results are in, and they signal a shift in the hierarchy of "hard science" capabilities.
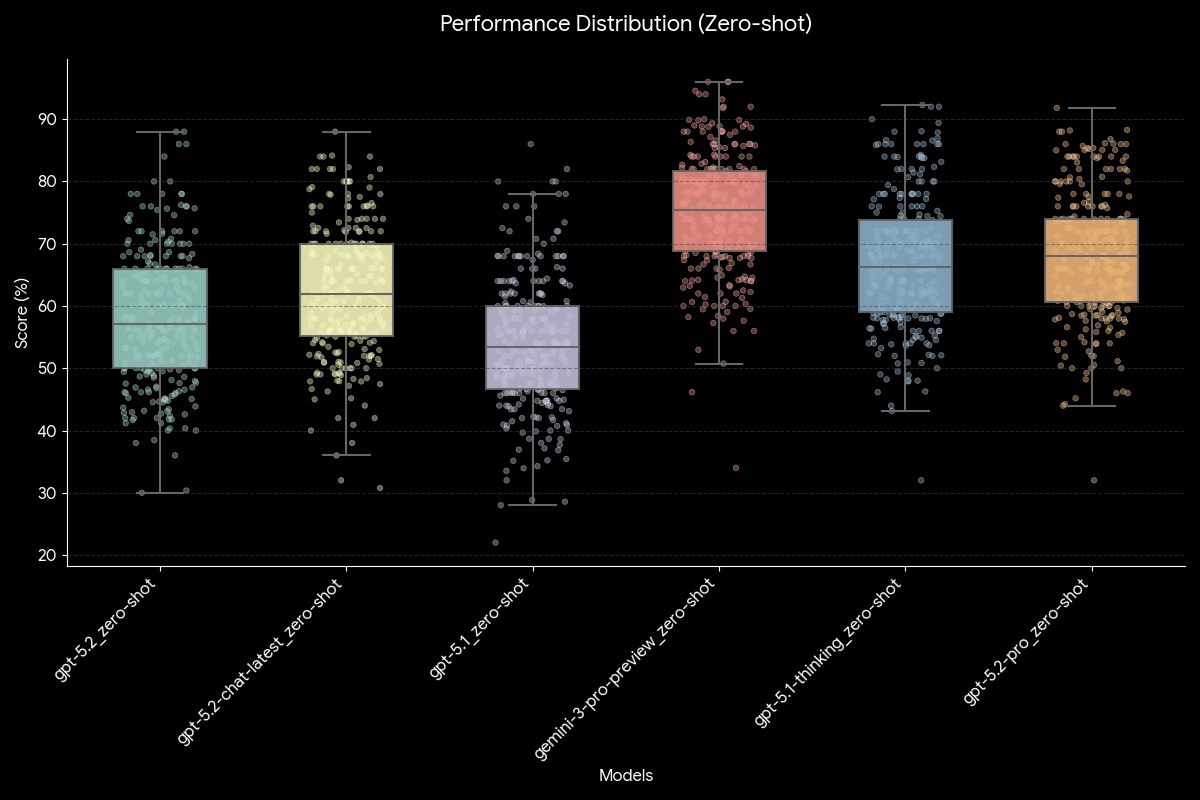
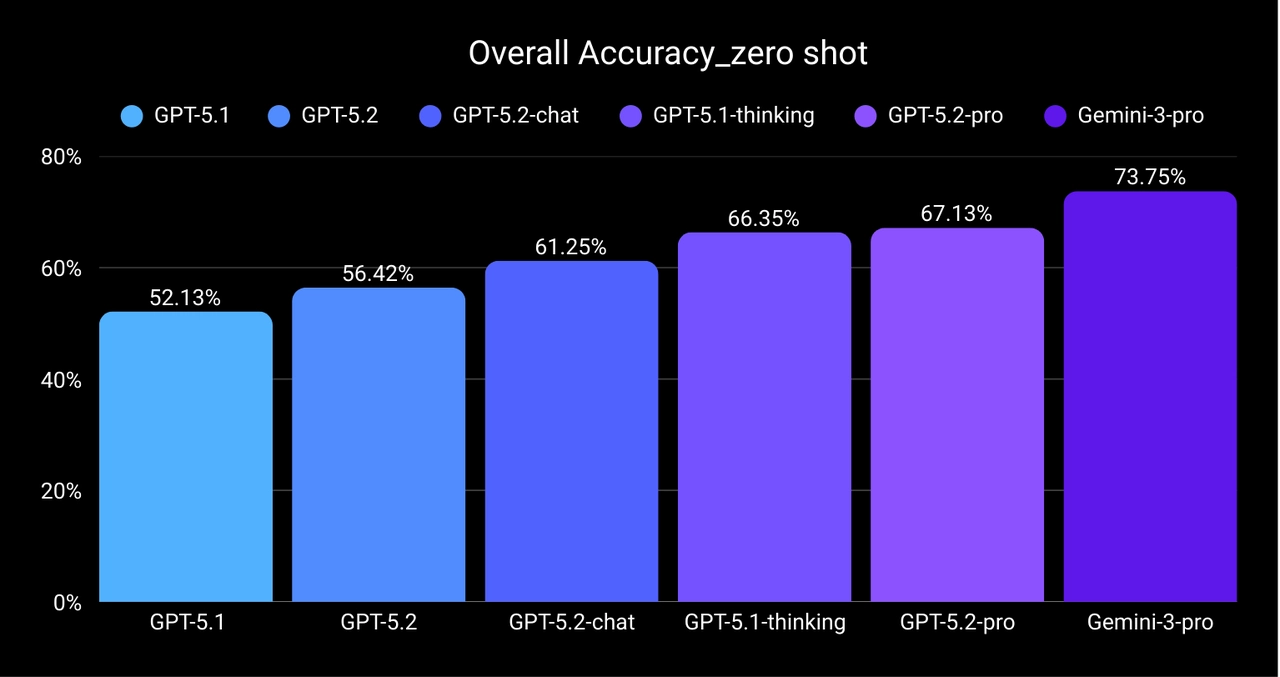
The Verdict: Gemini 3 Pro Leads in Specialized Knowledge
Contrary to the expectation that newer is always better, our data shows that Gemini 3 Pro Preview currently holds the edge in complex, high-stakes scientific domains. While the GPT-5 series demonstrates impressive reasoning, Gemini's underlying knowledge density in specialized fields appears superior.
In the Physics domain alone, which aggregates over 2,000 graduate-level questions, the performance gap is distinct. Gemini 3 Pro consistently ranks at the top, outperforming the GPT-5 series in subfields that require precise physical intuition and calculation.
Discipline Deep Dive: Where the Models Diverge
The aggregate scores tell only half the story. The true test of an expert model is its performance in "long-tail" disciplines—subjects that aren't just reasoning puzzles, but require deep, memorized professional knowledge.
Hard Physics: The Reasoning Test
Relativity is one of the most conceptually demanding subfields in our benchmark. Here, Gemini 3 Pro achieved a commanding 79.75% accuracy. In comparison, OpenAI's specialized reasoning model, GPT-5.1-Thinking, scored 74.68%, while the new GPT-5.2 Pro trailed at 70.89%. This suggests that for theoretical physics, Gemini's internal world model is more robust.
Specialized Agriculture: The Knowledge Test
In Aquaculture, a niche field often overlooked by general benchmarks, the difference is even more stark. Gemini 3 Pro maintained a robust 62.50% accuracy, proving its versatility. In contrast, GPT-5.2 Pro struggled significantly, achieving only 48.21% - a gap of over 14 percentage points.
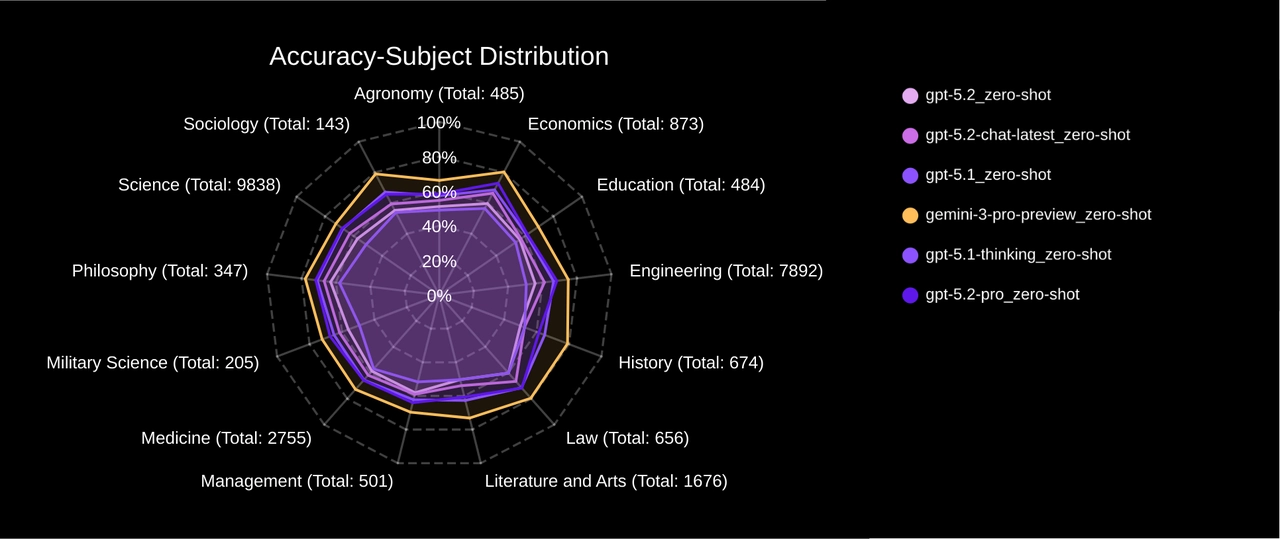
Conclusion
For developers and enterprises choosing between these frontier models, the SuperGPQA verdict is clear:
GPT-5.1-Thinking is a powerful tool for logic-heavy tasks, showing strong improvements over base models in reasoning-intensive questions.
However, Gemini 3 Pro currently reigns supreme in domain expertise. If your application requires handling specialized, graduate-level knowledge, from theoretical physics to agricultural science—Gemini 3 Pro is the statistical leader.
As the AI landscape evolves, SuperGPQA will continue to serve as the unbiased arena for measuring true machine intelligence.