Introduction
PIN (Paired and INterleaved multimodal documents) is a novel data format and large-scale dataset designed to solve persistent perceptual and reasoning errors in knowledge-intensive Large Multimodal Models (LMMs). Current LMMs often fail when interpreting complex visual data (like tables and charts) or deducing the relationships between images and text, largely because existing datasets separate these information streams.
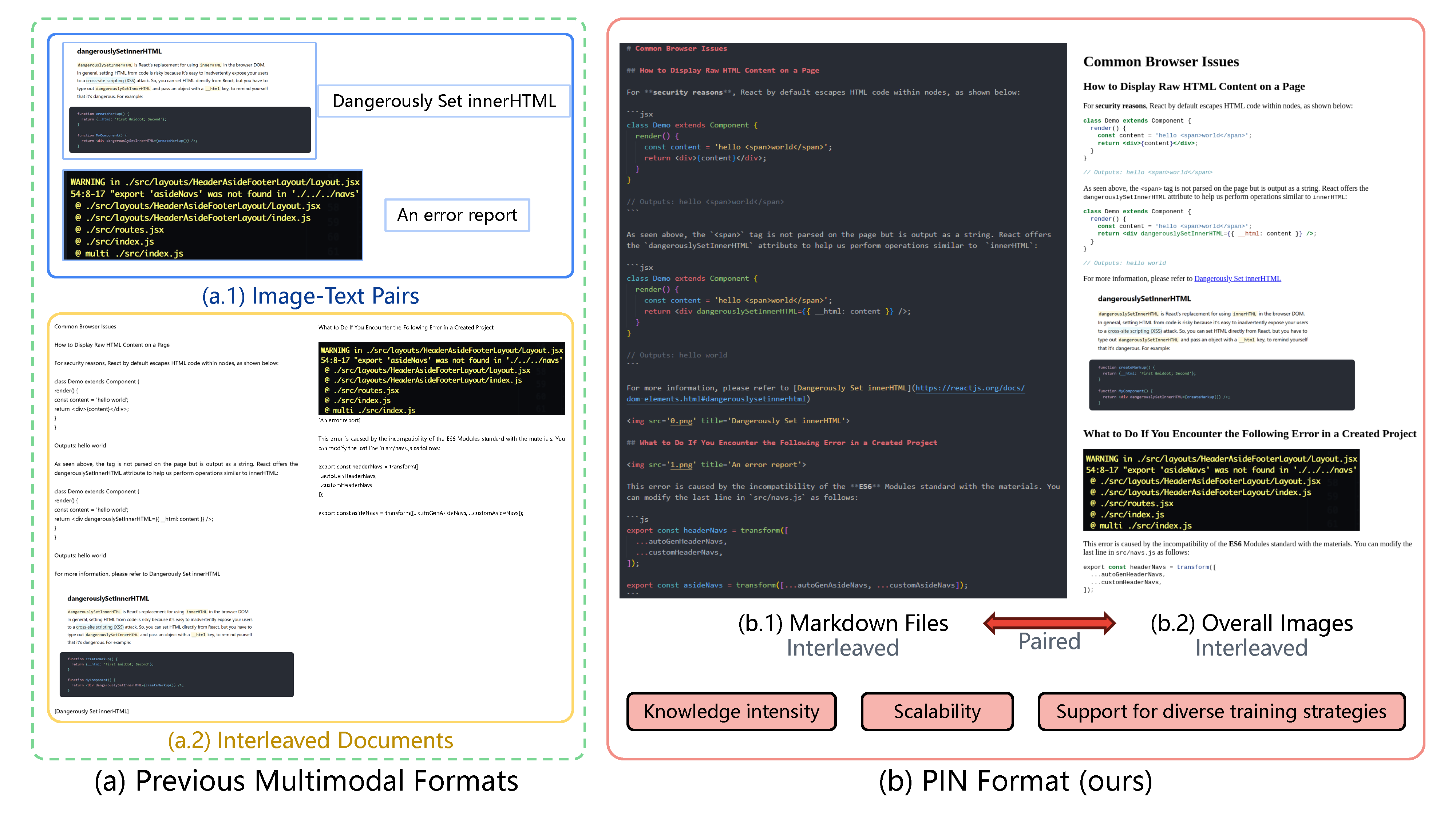
The PIN format directly addresses this by fostering a deeper, synergistic integration of visual and textual knowledge. Each document in the dataset uniquely combines:
A Semantically Rich Markdown File: This preserves the fine-grained textual structure, including headings, lists, and tables.
A Holistic Overall Image: This captures the complete document layout, providing the crucial spatial and visual context. By training on this dual representation, LMMs can learn to connect detailed text with its overarching visual layout, correcting the errors that plague current models.
To empower new research, we are releasing our large-scale, open-source dataset built on this format, compiled from diverse web and scientific sources (in English and Chinese). The dataset was first constructed at a scale of PIN-14M (~14 million documents) and, while maintaining the same high-quality standard, has now been successfully scaled up to PIN-200M (~200 million documents).
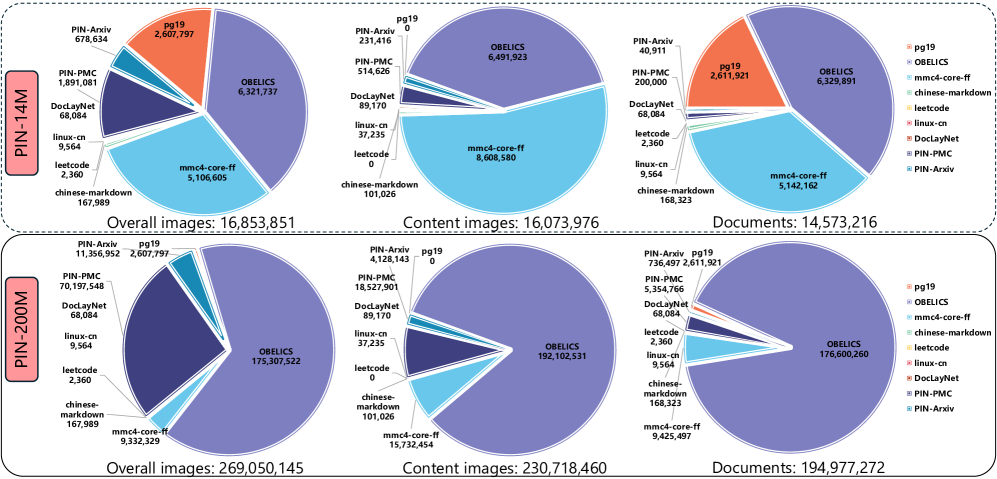
We process 9 subsets, including PIN-Arxiv, PIN-PMC, DocLayNet, Linux-CN, chinese-markdown, OBELICS, MMC4, leetcode, and PG19. (Note: We do not release the PIN-arXiv subset in the preview version.)

Equipped with detailed quality signals for easy filtering, the PIN datasets provide a foundational resource for developing and pre-training the next generation of powerful, knowledge-intensive LMMs.
Dataset Overview
Overall, the PIN-200M dataset comprises nearly 200 million documents, with a mean ITIF of 3.24 and a high prevalence of knowledge-intensive attributes. These characteristics indicate its nature as a large-scale, knowledge-intensive resource.
- Documents
- Overall images
- Content images
Data Distribution
Data Samples
BibTeX
@article{DBLP:journals/corr/abs-2406-13923,
author = {Junjie Wang and
Yuxiang Zhang and
Minghao Liu and
Yin Zhang and
Yatai Ji and
Weihao Xuan and
Nie Lin and
Kang Zhu and
Zhiqiang Lin and
Yiming Ren and
Chunyang Jiang and
Yiyao Yu and
Zekun Wang and
Tiezhen Wang and
Wenhao Huang and
Jie Fu and
Qunshu Lin and
Yujiu Yang and
Ge Zhang and
Ruibin Yuan and
Bei Chen and
Wenhu Chen},
title = {{PIN:} {A} Knowledge-Intensive Dataset for Paired and Interleaved
Multimodal Documents},
journal = {CoRR},
volume = {abs/2406.13923},
year = {2024}
}