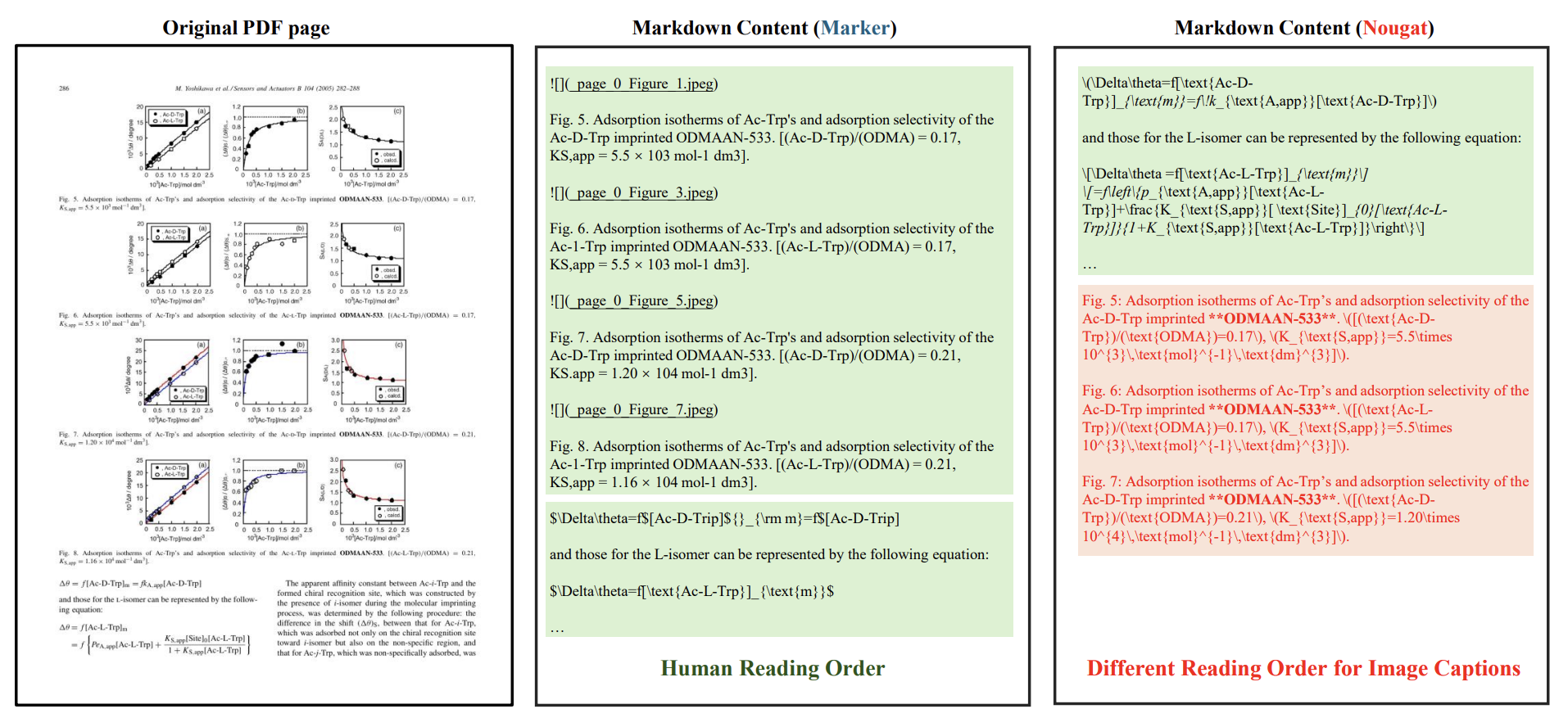
Introduction
OmniDocBench is a comprehensive benchmark for evaluating AI in document parsing and content extraction. Addressing the limitations of existing benchmarks—namely their narrow coverage and simplistic evaluations. It provides high-quality annotations across 9 diverse sources, including academic papers, handwritten notes, and densely typeset newspapers. OmniDocBench effectively reveals weaknesses in top-performing models when they process complex layouts and content structures, highlighting its challenging nature and its potential to drive future progress in Document AI.
Dataset Overview
OmniDocBench contains 1355 pages across 9 distinct document types, with over 100,000 fine-grained annotations.
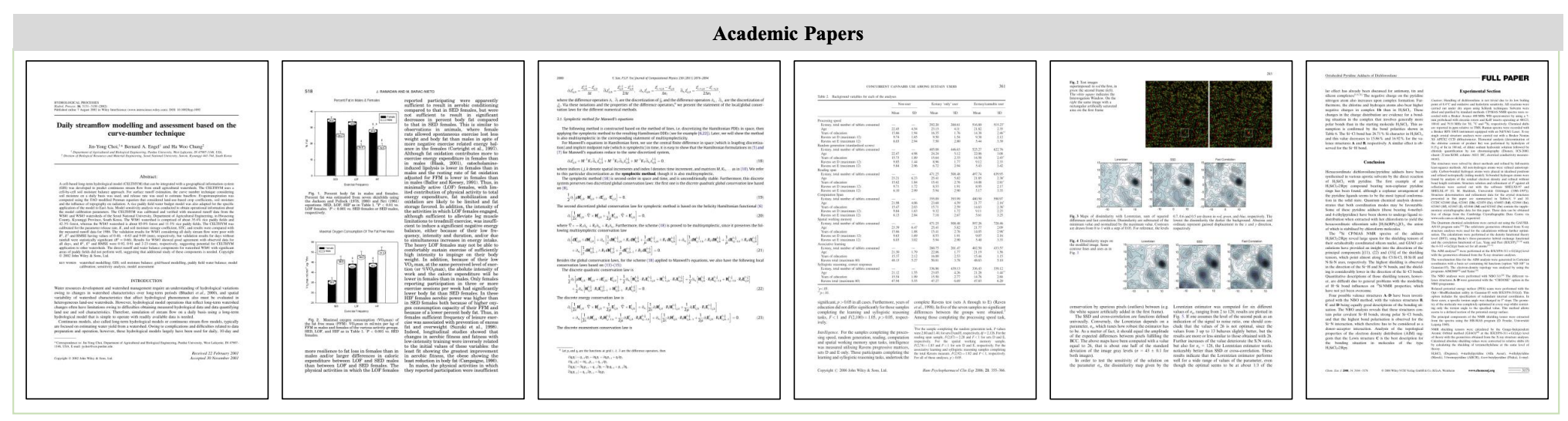
- Academic Papers
- Slides
- Books
- Textbooks
- Exam Papers
- Notes
- Megazines
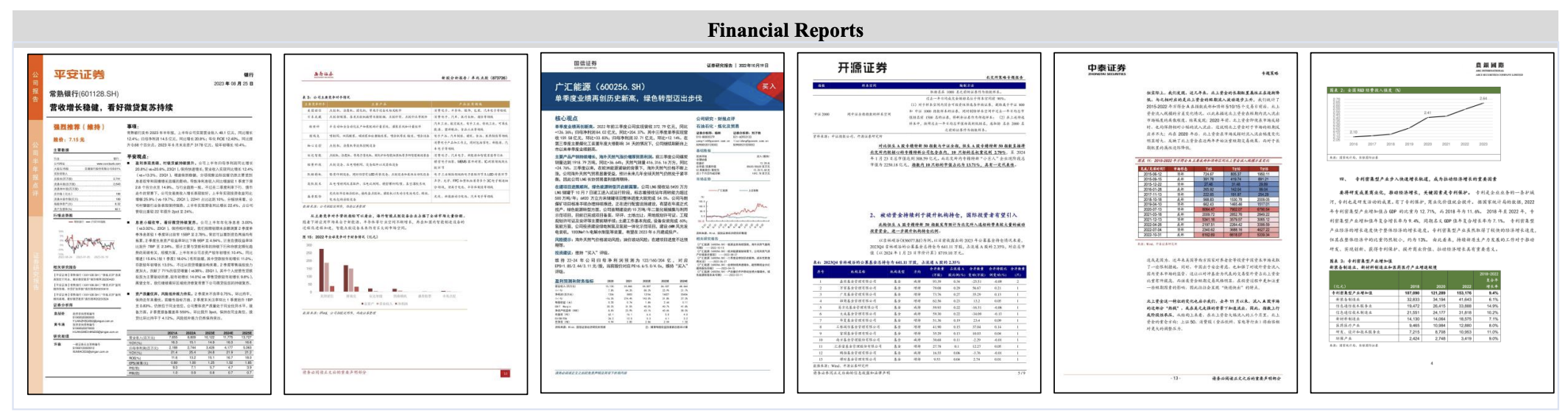
- Financial Reports
- Newspapers
Dataset Overview
Data Samples
Leaderboard
| Overall | Model | Model Type | Size | TextEdit | FormulaCDM | TableTEDS | TableTEDS-S | Read OrderEdit |
|---|---|---|---|---|---|---|---|---|
| 191.93 | PaddleOCR-VL | Specialized VLMs | 0.9B | 0.039 | 88.67 | 91.01 | 94.85 | 0.048 |
| 290.67 | MinerU2.5 | Specialized VLMs | 1.2B | 0.047 | 88.46 | 88.22 | 92.38 | 0.044 |
| 389.15 | Qwen3-VL-235B-A22B-Instruct | General VLMs | 235B | 0.069 | 88.14 | 86.21 | 90.55 | 0.068 |
| 88.85 | MonkeyOCR-pro-3B | Specialized VLMs | 3B | 0.075 | 87.25 | 86.78 | 90.63 | 0.128 |
| 88.41 | dots.ocr | Specialized VLMs | 3B | 0.048 | 83.22 | 86.78 | 90.62 | 0.053 |
| 88.03 | Gemini-2.5 Pro | General VLMs | - | 0.075 | 85.82 | 85.71 | 90.29 | 0.097 |
| 87.13 | MonkeyOCR-3B | Specialized VLMs | 3B | 0.075 | 87.45 | 81.39 | 85.92 | 0.129 |
| 87.02 | Qwen2.5-VL | General VLMs | 72B | 0.094 | 88.27 | 82.15 | 86.22 | 0.102 |
| 87.01 | Deepseek-OCR | Specialized VLMs | 3B | 0.073 | 83.37 | 84.97 | 88.8 | 0.086 |
| 86.96 | MonkeyOCR-pro-1.2B | Specialized VLMs | 1.2B | 0.084 | 85.02 | 84.24 | 89.02 | 0.13 |
| 86.73 | PP-StructureV3 | Pipeline Tools | - | 0.073 | 85.79 | 81.68 | 89.48 | 0.073 |
| 85.59 | Nanonets-OCR-s | Specialized VLMs | 3B | 0.093 | 85.9 | 80.14 | 85.57 | 0.108 |
| 85.56 | MinerU2-VLM | Specialized VLMs | 0.9B | 0.078 | 80.95 | 83.54 | 87.66 | 0.086 |
| 83.21 | Dolphin-1.5 | Specialized VLMs | 0.3B | 0.092 | 80.78 | 78.06 | 84.1 | 0.08 |
| 82.67 | InternVL3.5 | General VLMs | 241B | 0.142 | 87.23 | 75 | 81.28 | 0.125 |
| 81.79 | olmOCR | Specialized VLMs | 7B | 0.096 | 86.04 | 68.92 | 74.77 | 0.121 |
| 80.98 | POINTS-Reader | Specialized VLMs | 3B | 0.134 | 79.2 | 77.13 | 81.66 | 0.145 |
| 80.33 | InternVL3 | General VLMs | 78B | 0.131 | 83.42 | 70.64 | 77.74 | 0.113 |
| 78.83 | Mistral OCR | Specialized VLMs | - | 0.164 | 82.84 | 70.03 | 78.04 | 0.144 |
| 75.51 | Mineru2-pipeline | Pipeline Tools | - | 0.209 | 76.55 | 70.9 | 79.11 | 0.225 |
| 75.02 | GPT-4o | General VLMs | - | 0.217 | 79.7 | 67.07 | 76.09 | 0.148 |
| 74.82 | OCRFlux | Specialized VLMs | 3B | 0.193 | 68.03 | 75.75 | 80.23 | 0.202 |
| 74.67 | Dolphin | Specialized VLMs | 0.3B | 0.125 | 67.85 | 68.7 | 77.77 | 0.124 |
| 71.3 | Marker-1.8.2 | Pipeline Tools | - | 0.206 | 76.66 | 57.88 | 71.17 | 0.25 |
Further Analysis
In order to gain a deeper understanding of the performance of our model, this section presents the results of a series of detailed analysis experiments.
Vary Standards

Data Display






BibTeX
@misc{ouyang2024omnidocbench,
title = "OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations",
author = "Linke Ouyang and Yuan Qu and Hongbin Zhou and Jiawei Zhu and Rui Zhang and Qunshu Lin and Bin Wang and Zhiyuan Zhao and Man Jiang and Xiaomeng Zhao and Jin Shi and Fan Wu and Pei Chu and Minghao Liu and Zhenxiang Li and Chao Xu and Bo Zhang and Botian Shi and Zhongying Tu and Conghui He",
eprint = "2412.07626",
archivePrefix = "arXiv",
year = "2024",
primaryClass = "cs.CV",
url = "https://arxiv.org/abs/2412.07626"
}