DR.DOCBENCH
Expert-Level and Difficult
Document Parsing
Difficulty-aware evaluation across 52 domains, targeting cases where state-of-the-art systems struggle.
Difficulty-aware evaluation across 52 domains, targeting cases where state-of-the-art systems struggle.
DR.DOCBENCH is a subject-diverse, difficulty-aware, expert-level benchmark designed to close the evaluation gap — targeting document pages where state-of-the-art systems struggle.
Pages are selected around cases where strong parsers disagree, surfacing genuinely hard documents instead of easy OCR wins.
DR.DOCBENCH spans 52 BISAC domains, from music and chemistry to law, medicine, reference works, games, and technical manuals.
The benchmark covers fine-grained layout, recognition, and domain-specific structures that ordinary document parsing tests often miss.
Formulas use CDM and edit distance, tables use TEDS/TEDS-S, while text and reading order are scored with normalized edit distance.
DR.DOCBENCH spans 52 BISAC subject domains with 4,514 annotated pages, combining difficulty-aware document selection with fine-grained labels for layout, recognition, and expert-domain structures.

Overall evaluation across text extraction, formula recognition, table structure, and reading order. Edit-distance metrics are lower-is-better, while CDM, TEDS, TEDS-S, and Overall are higher-is-better.
| Model | Size | Access | Text Edit↓ | Formula | Table | Order Edit↓ | Overall↑ | ||
|---|---|---|---|---|---|---|---|---|---|
| Edit↓ | CDM↑ | TEDS↑ | TEDS-S↑ | ||||||
| Specialized VLMs | |||||||||
| MinerU 2.5 | 1.2B | Open | 0.33 | 0.51 | 24.15 | 55.85 | 63.70 | 0.30 | 54.37 |
| PaddleOCR | 0.9B | Open | 0.73 | 0.42 | 30.73 | 51.79 | 59.94 | 0.71 | 34.78 |
| General VLMs | |||||||||
| Qwen3.5-Flash | 3B | Open | 0.26 | 0.32 | 35.69 | 46.24 | 54.38 | 0.26 | 57.51 |
| Qwen3.5-122B-A10B | 10B | Open | 0.23 | 0.32 | 32.54 | 38.31 | 44.99 | 0.23 | 56.32 |
| Qwen3.5-Plus | 17B | Open | 0.25 | 0.31 | 30.40 | 49.77 | 58.23 | 0.26 | 57.32 |
| Nemotron-Nano-12B | 12B | Open | 0.62 | 0.76 | 12.82 | 27.03 | 34.09 | 0.564 | 30.33 |
| Kimi-K2.5 | 32B | Open | 0.19 | 0.35 | 27.04 | 51.98 | 61.09 | 0.18 | 60.38 |
| Claude Opus 4.6 | — | Closed | 0.22 | 0.37 | 32.02 | 49.21 | 58.12 | 0.19 | 60.19 |
| Doubao-Seed-1.6-Vision | — | Closed | 0.34 | 0.31 | 41.28 | 33.93 | 42.16 | 0.28 | 53.14 |
| Gemini 3.1 Pro | — | Closed | 0.22 | 0.35 | 32.22 | 51.26 | 59.03 | 0.21 | 60.13 |
| GPT-4o | — | Closed | 0.37 | 0.47 | 36.02 | 30.14 | 38.62 | 0.31 | 49.73 |
| GPT-5.5 | — | Closed | 0.19 | 0.36 | 34.55 | 48.90 | 58.96 | 0.17 | 61.94 |
Two qualitative probes from the analysis section: borderless table reconstruction and schema-faithful music transcription. Both reveal failures that text-only OCR accuracy would miss.
Wireless, or borderless, tables expose how strongly models depend on visible grid lines. From full-line to wireless tables, Kimi drops from 49.1 to 21.4 TEDS, while Doubao collapses to 8.1, near-random performance.
The failure is not just table recognition. Doubao can miss the target table when it falls on the second page of the context window, attending instead to prior-page content and recovering spurious tables. Kimi shows a different failure: content can be right while the required HTML format is ignored.





Optical Music Recognition is a new subject absent from prior document benchmarks. It requires simultaneous visual understanding of clefs, noteheads, key and time signatures, articulations, and schema-faithful MusicXML generation.
To anchor difficulty, the paper computes a cross-document null reference: the mean pairwise edit distance across all six ground-truth MusicXML files. This null is 0.624, approximately the score of emitting an arbitrary unrelated score. No evaluated model beats it.
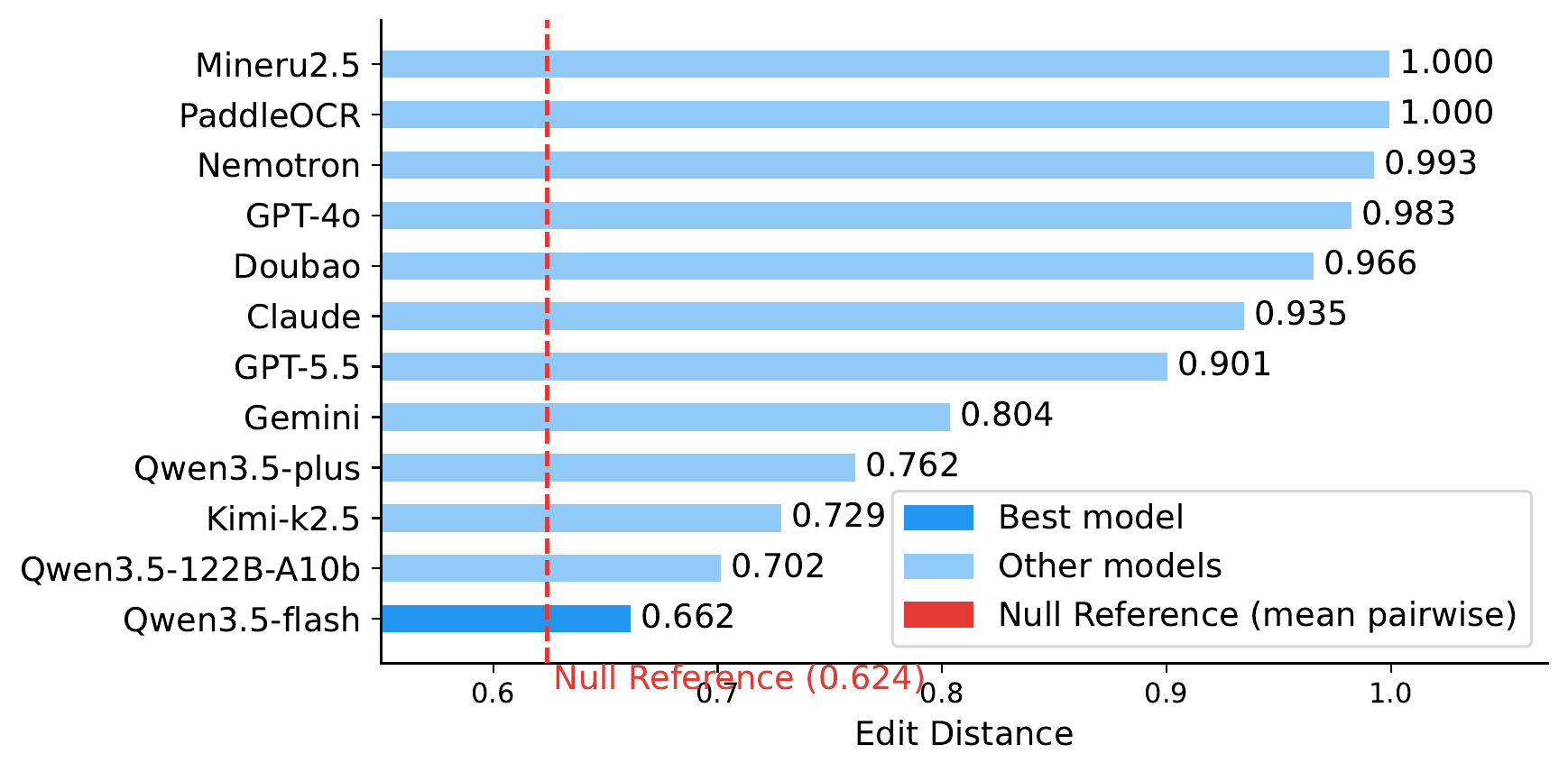
From systematic evaluation of 12 models across subjects, content types, and structural attributes.
The leading group is tight, but strengths differ: GPT-5.5 leads overall, Kimi-K2.5 is strong on tables, and Doubao-Seed-1.6-Vision has the best formula CDM.
Design, Games, Medical, and Antiques & Collectibles also recur as difficult cases, often due to dense layouts or domain-specific structure.
Research reports are challenging across most models, while PPT-to-PDF shows large variation between models.
Background shading makes cell localization and table-structure reconstruction less reliable.
Rotated text, especially 90-degree rotation, is harder than normal orientation for most models.
High-performing parsers tend to produce compact, well-structured outputs rather than simply longer generations.
MinerU achieves the strongest table scores, though specialized systems are disadvantaged on prompt-dependent outputs.
No evaluated model beats the 0.624 null reference for MusicXML transcription.
If you use DR.DOCBENCH in your research, please cite:
@article{yang2026drdocbench,
title = {DR.DOCBENCH: A Comprehensive Benchmark for Expert-Level
and Difficult Document Parsing},
author = {Minglai Yang and Xinyan Velocity Yu and Pengyuan Li and Xinyu Guo and Zhenting Qi and Konwoo Kim and Longtian Ye and
Xiaolong Luo and Jinhe Bi and Henry Zhang and Haris Riaz and Xuan Zhang and Yunze Xiao and Bangya Liu and Ningshan Ma
and Tom Tang and Yunfei Zhao and Qunshu Lin and Zihan Wang and Minghao Liu and Michael Lingzhi Li and Yilun Du and
Jesse Thomason and Rogerio Feris and Alex Pentland and Zexue He},
year = {2026},
journal = {arXiv preprint},
}